- Disrupción Consciente
- Posts
- VibeCodeando que es gerundio
VibeCodeando que es gerundio
Miguel Barreiro
9 de diciembre de 2025
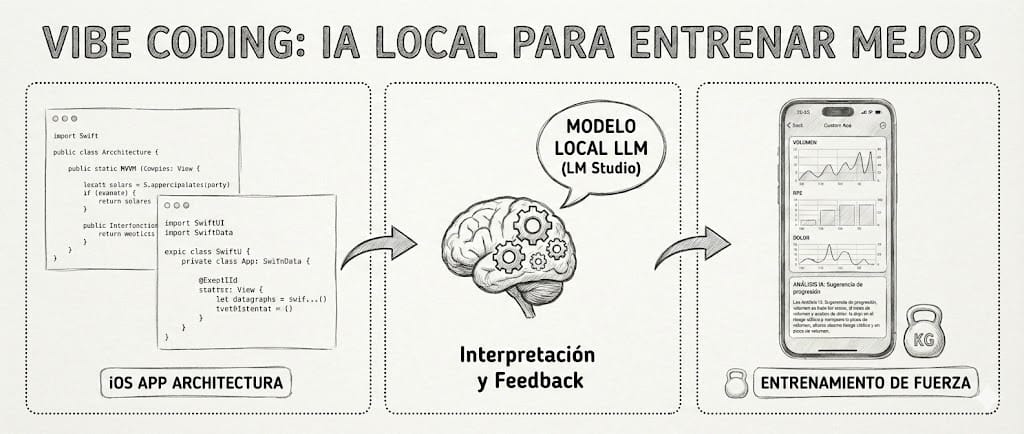
Llevo muchos años metido en el mundo de la IA y buena parte de 2025 cacharreando con el vibe coding. Este fin de semana he terminado mi primer proyecto “real” de vibe coding: una app nativa de iOS que se habla con un LLM local corriendo en mi Mac, y que uso para algo muy poco teórico: entrenar mejor y lesionarme menos.
No es un experimento de laboratorio ni una demo para una charla, es una herramienta que ya estoy usando para mi propio entrenamiento de fuerza, con un contexto bastante específico: historial de síndrome piramidal, dolor ciático recurrente y cierta afición a sobrecargar demasiado rápido cuando las cosas van bien. Mezcla explosiva.
En vez de buscar otra app de fitness (he probado un ciento), decidí construir la mía. Y, ya que estamos en 2025, hacerlo combinando:
app nativa en Swift/SwiftUI,
analítica de entrenamiento y heurísticas de seguridad en código,
y un LLM local vía LM Studio para la parte de interpretación y feedback.
El problema que quería resolver
La mayoría de apps de entrenamiento que he probado tienen el mismo patrón: muchas gráficas bonitas, algo de RPE, recomendadores genéricos y todos tus datos subidos alegremente a la nube de alguien.
Mi caso no es genérico:
Necesito trackear dónde duele (lado afectado, tipo de molestia, intensidad).
Necesito vigilar picos de volumen: si aumento más de un 20 % el tonelaje semanal en ciertos patrones de movimiento, sé que estoy jugando con fuego.
Y necesito que el sistema me ayude a recordar patrones de riesgo: “cada vez que subes el peso muerto y encadenas dos semanas de RPE alto, acabas tocado del nervio”.
No me sirve un “has hecho 5 entrenos esta semana, enhorabuena” con confeti. Me sirve saber si lo que estoy haciendo tiene sentido para mi cuerpo, no para un usuario promedio.
Qué hace realmente
El desarrollo es simple, pero aún con todo tiene:
5.400+ líneas de Swift
Arquitectura MVVM
Persistencia con SwiftData
Gráficas con Swift Charts
Y un cliente HTTP que se conecta a LM Studio en mi Mac, con un modelo tipo
openai/gpt-oss-20bexpuesto vía API.
A alto nivel, la app hace tres cosas:
Registra entrenamientos con mucho más detalle que “peso x repes”
Para cada serie guardo:reps, kilos, RPE
nivel de molestia
flag de dolor ciático y lado afectado
Calcula métricas y riesgos en código nativo, no en el LLM
Un servicio de analítica en Swift:calcula tonelaje total y por grupo muscular,
detecta picos de volumen (>20 % vs semana anterior),
marca semanas con RPE medio sostenido alto,
detecta si ha habido 2+ sesiones con dolor ciático en los últimos 10 días.
Pide al LLM solo que interprete lo ya calculado
El modelo local recibe:un resumen de la semana,
un histórico de hasta 50 sesiones,
y un conjunto de banderas ya pre-calculadas (riesgo ciático, picos de volumen, etc.).
Con eso genera:
un análisis de la semana,
sugerencias de progresión conservadora,
avisos cuando ve patrones que no le gustan.
Nada de que el modelo “descubra” los riesgos. Los riesgos los detecta código determinista. El LLM se limita a ponerles palabras encima.
Arquitectura: separación radical entre cálculo e interpretación
La decisión más importante del diseño ha sido esta:
El modelo de lenguaje nunca calcula nada crítico ni decide si algo es seguro.
Solo interpreta y sugiere.
Toda la lógica sensible vive en Swift:
Picos de volumen, en base a % sobre semana previa.
Heurísticas de dolor ciático (2+ sesiones en 10 días).
RPE sostenido alto (más de 8,5 durante al menos dos semanas).
Eso significa que:
Si algo falla, tengo tests unitarios para reproducirlo.
Puedo auditar por qué una semana se ha marcado como de riesgo.
Puedo cambiar las reglas sin tocar prompts.
El LLM, en cambio, recibe un JSON con todo esto ya masticado y un prompt largo (sí, largo) explicando:
mi contexto (historial de piramidal, qué ejercicios suelen ser problemáticos, etc.),
lo que puede y lo que no puede hacer,
y el formato exacto en el que debe responder (otro JSON estructurado).
Su trabajo no es “decidir”: es explicarme con detalle lo que ya sabemos de mis datos, y proponer ajustes razonables.
Por qué IA local y no “otra API en la nube”
Integrar LM Studio y un modelo local en mi Mac tenía tres motivaciones claras:
Privacidad
Estoy hablando de dolor, limitaciones funcionales y patrones de lesión. No quiero eso viajando alegremente por media internet.
Con LM Studio todo se queda en mi red local: iPhone → WiFi → Mac → modelo.Coste y control
Sin cuotas, sin límites de llamadas, sin logs externos, sin depender de que alguien decida cambiar una política de pricing o apagar un endpoint.Aprender en serio sobre edge AI
No es lo mismo leer sobre “modelos en el borde” que pelearte con:latencias reales de un modelo de 20B,
prompts largos en modelos open-source,
y las diferencias respecto a usar un modelo frontier.
Ese aprendizaje práctico, con un caso de uso que me importa, era parte del objetivo.

Lo bueno, lo malo y lo interesante del proyecto
Después de varias horas metido en Xcode y LM Studio, me quedo con varias ideas:
1. Un side project técnico de verdad obliga a pensar como arquitecto y como usuario a la vez.
No basta con que “compile”: tiene que encajar en mi rutina real de entreno, con el mínimo fricción posible. Eso te obliga a priorizar.
2. Los modelos open-source responden mucho mejor con prompts explícitos y largos.
El system prompt tiene alrededor de 70 líneas. A un frontier model le podrías decir lo mismo en tres.
Aquí no. Si quieres que siga reglas, se las tienes que grapar delante de la cara.
3. La privacidad puede ser una feature, no un freno.
“Funciona solo en tu red local, con tu propio modelo, sin subir datos a ningún sitio” no es una limitación, es parte del valor.
Especialmente cuando hablamos de salud.
4. No hay IA responsable sin tests aburridos detrás.
Los tests unitarios no salen en las capturas de pantalla, pero son los que garantizan que:
los cálculos de tonelaje son correctos,
las banderas de riesgo se disparan donde deben,
y el JSON que mando/recibo es el que creo que mando/recibo.
Sin eso, lo único que tendrías es una interfaz bonita conectada a un modelo que a veces acierta y a veces no, sin saber por qué.
Qué viene después
El proyecto no está terminado, y esa es precisamente la idea. En la lista de cosas que quiero ir añadiendo están:
Gráficas de progresión por ejercicio concreto (por ejemplo, ver claramente la curva de la sentadilla búlgara en los últimos meses).
Persistencia del feedback de la IA para revisar cómo han ido cambiando las recomendaciones con el tiempo.
Integración opcional con Apple Health para cruzar sesiones con sueño, pasos, etc.
Y, a medio plazo, explorar modelos más pequeños y rápidos que puedan correr directamente en el propio iPhone.
No creo que esto sea algún día un producto público. De momento, es mi propio laboratorio: un sitio donde juntar tres cosas que me importan bastante:
entrenar mejor,
entender mi cuerpo,
y seguir profundizando en cómo integrar IA en productos reales
Si te interesa la intersección entre salud, entrenamiento de fuerza, IA local y desarrollo nativo, este tipo de proyectos son el sitio donde las ideas dejan de ser teoría y se convierten en decisiones de código, arquitectura y experiencia de usuario. Y ahí es donde de verdad se aprende.